
Whenever we think about AI chips, one name that comes to mind is NVIDIA. It already covers over 80% market. However, there is one player who is giving NVIDIA a tough time in China, and that is Huawei. According to the report from Bernstein Research NVIDIA’s China AI chip market share drops to 8% by 2026 (from 66% in 2024, 54% in 2025), while Huawei captures around 50% market share.
That’s why I have created this detailed comparison about NVIDIA vs Huawei AI Chips, where i have talked about chip portfolios, architectures, training and inference performance, software ecosystems, real-world adoption, and a lot more. Additionally, I have touched on how geopolitics and export controls are influencing product strategy and market access.
NVIDIA AI Chips Explained
NVIDIA’s AI chips are the default choice for training large AI models. Here are the details about its hardware strategy, technical strengths, performance, and software stack.
NVIDIA’s AI Chip Portfolio
As of January 2026, NVIDIA’s AI chip portfolio centers around data center GPUs for training and inference, spanning Hopper, Blackwell generations, with the newly launched platform Rubin. Here’s the complete portfolio of the company:
Architecture and Manufacturing Process
NVIDIA’s AI chips, like the current Blackwell B200 and GB200 GPUs, use a dual-chip design where two massive dies (208 billion transistors total) connect at 10 TB/s speed to act as one powerful unit, which is built on TSMC’s advanced 4NP 4nm process for best efficiency. Hopper chips (H100/H200) use a single die on TSMC 4N, while new Rubin adds HBM4 memory, all packaged with CoWoS tech stacking up to 192GB of fast HBM3E for AI tasks.
Performance in AI Training and Inference
NVIDIA’s Blackwell GPUs like the B200 and GB200 lead in AI performance, which delivers up to 4x faster training and 30x faster inference compared to the earlier Hopper H100 for large language models.
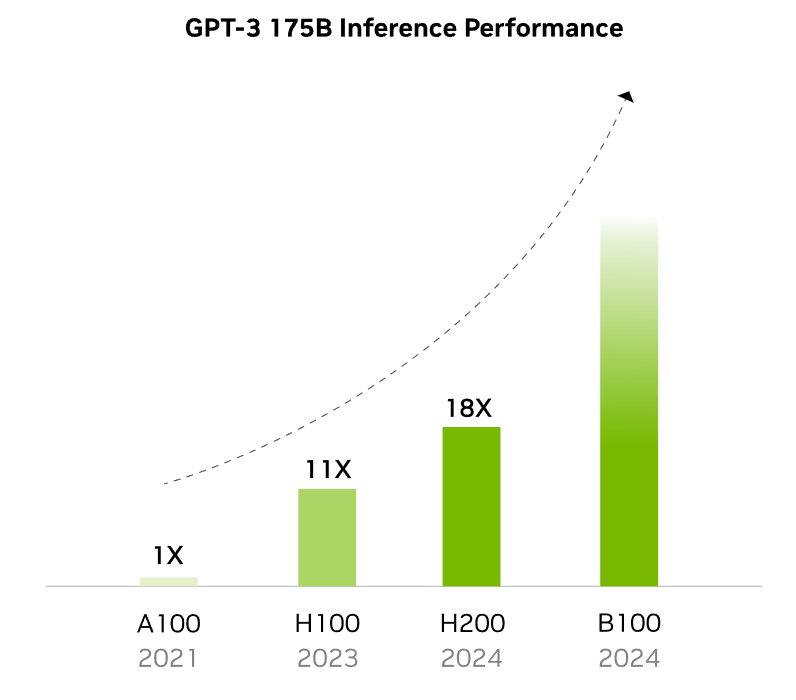
The B200 achieves 9 PFLOPS dense FP4 (18 PFLOPS sparse) for inference and 4.5/9 PFLOPS FP8, enabling trillion-parameter models with lower latency via second-gen Transformer Engine and NVLink 5 at 1.8 TB/s bandwidth. In MLPerf benchmarks, B200 systems show 2.2x faster Llama 2 70B fine-tuning and 2x GPT-3 175B pre-training versus H100, while GB200 NVL72 racks hit 1.4 exaFLOPS FP4 for scaled workloads.
Software Ecosystem and CUDA Advantage
The software ecosystem of NVIDIA’s AI chips revolves around CUDA, which is a parallel computing platform that allows developers to write code in C/C++ to harness GPU power for AI tasks. It includes libraries like cuDNN for deep learning, TensorRT for inference, and cuBLAS for linear algebra, plus support for PyTorch, TensorFlow, and JAX via pre-built containers.
The CUDA advantage lies in its vast community, 15+ years of refinement, and “write once, run anywhere” portability across NVIDIA hardware. This creates a moat for the company, locking in hyperscalers like AWS and Azure while enabling the deployment of trillion-parameter models.
Huawei AI Chips Explained
Huawei’s AI chips are built for quite a very different environment. Instead of competing in the global markets, the Chinese tech giant focuses on serving its domestic AI market under strict technology restrictions.
Huawei Ascend AI Chip Series Overview
Huawei’s Ascend AI chip series focuses on NPUs for AI workloads, with 910 models in production and 950 series launching in 2026. Here’s everything you need to know about:
Chip Architecture and Process Technology
The Ascend AI chips use the proprietary Da Vinci architecture. It features scalable AI cores including DaVinci Max/Lite/Tiny variants, which are optimized for neural networks with vector processing units (VPUs), matrix multiplication engines (MTEs), and task dispatching for high parallelism.
Current 910B/C models employ a dual-chiplet design with 32 Da Vinci Max cores, hybrid SIMD/SIMT execution for better CUDA compatibility, and stacked HBM2E memory, all on SMIC’s N+2 7nm (DUV-based multi-patterning) process node.
Performance in AI Workloads
Huawei Ascend AI chips deliver strong performance in AI workloads. Here are some points from the Huawei Connect 2025 keynote:
- Ascend 950 chip specs: 1 PFLOPS FP8/MXFP8/HiF8; 2 PFLOPS MXFP4 compute
- 950 vector processing: SIMD/SIMT hybrid for better CUDA compatibility
- 950 interconnect: 2 TB/s bandwidth between chips
- Atlas 950 SuperPoD (8,192 chips): 4.91M TPS training (17x prior gen), 19.6M TPS inference (26x gain)
- Atlas 960 SuperPoD (15,488 chips): 30 EFLOPS FP8, 60 EFLOPS FP4 total compute
- Key advantage: SuperPoDs operate as unified “logical machines” for massive AI clusters
Software Stack and CANN Framework
The Ascend AI chips rely on the CANN (Compute Architecture for Neural Networks) framework as their core software stack, which is similar to CUDA, offering low-level tools, runtime libraries, and over 1,000 operators for high-performance AI execution. CANN includes AscendCL for unified programming across edge, cloud, and devices, supporting custom operators via TBE-DSL/TBE-TIK modes, graph optimization, and backward compatibility for easy code deployment.
It also pairs with MindSpore (Huawei’s PyTorch-like framework) for end-to-end development via MindStudio, plus MindX for model conversion from PyTorch/TensorFlow. However, full optimization often requires manual tweaks and Huawei engineers for the best results.
Performance Comparison
| Metric | NVIDIA (Blackwell B200/GB200) | Huawei (Ascend 910C/950) |
| Single Chip Peak | 9 PFLOPS FP4 inference, 4.5 PFLOPS FP8 | 950: 1 PFLOPS FP8, 2 PFLOPS FP4 |
| Rack-Scale Training | GB200 NVL72: 1.4 EFLOPS FP4 | Atlas 950 SuperPoD: 4.91M TPS (17x prior) |
| Rack-Scale Inference | 30x vs H100 (tokens/sec) | Atlas 950: 19.6M TPS (26x prior); 960: 80.5M TPS |
| Cluster Scale | NVLink 576 GPUs (~2027) | Atlas 960: 15,488 chips, 60 EFLOPS FP4 |
Key Notes: NVIDIA prioritizes per-chip raw compute and MLPerf-validated gains vs Hopper. On the other hand, Huawei highlights cluster scaling (8K-15K chips) and internal generational leaps, claiming SuperPoD superiority over NVIDIA’s largest announced racks in total throughput.
NVIDIA vs Huawei in the AI Chip Race
- NVIDIA: Powers 80-90% global AI (Microsoft Azure, AWS, Google); China giants like ByteDance/Alibaba approved for H200 imports Jan 2026.
- Huawei: Commands ~50% China market share (up from NVIDIA’s 8%), adopted by Baidu, state telecoms, and cloud units; minimal Western presence.
However, geopolitical and regulatory factors are now directly impacting AI hardware decisions. US export controls block NVIDIA’s top AI chips, like the Blackwell, from being shipped to China, forcing the company to sell downgraded H200/H20 versions there while maintaining global dominance.
Huawei has benefited from this policy, as its Ascend chips now hold around 50% of China’s AI chip market through domestic manufacturing on SMIC’s 7nm nodes despite lacking advanced EUV tools.
FAQs
No, Huawei’s Ascend 910C reaches about 60-80% of NVIDIA H100’s single-chip performance, though their clusters compete better at scale.
Yes, Huawei already holds ~50% China market share in 2026 and is rapidly displacing NVIDIA through government support and cheaper domestic supply.
Yes, NVIDIA powers 80-90% of global AI workloads via CUDA ecosystem dominance outside China.


